Training models to hallucinate flappy bird
A few weeks ago, my friend Sarthak Mangla and I attended the Kleiner Perkins Fellow hackathon. We were introduced to each other the day before, and on the day of, we had no idea what we wanted to/could build in the span of 24 hours.
After an hour of brainstorming, we kept thinking about Oasis, a semi-playable version of Minecraft with no predefined logic or inherent game engine released by Decart last year. Some images of gameplay can be seen below.

Inspired by Oasis, we eventually decided on training models to hallucinate 2D games. Retrospectively, this may not have been the best idea for our sleep schedules or sanity 😭. Our first attempt involved Super Mario, but we quickly realized that a) we were severely restricted on compute and b) creating training data for a game with complex controls/mechanics was a lot more difficult than we expected. By hour 8, we decided to abandon our initial idea and instead focused on a simpler game—Flappy Bird.
State-Space Models
Given our limitations (especially time), we decided to forego the typical setup of video-based diffusion and instead created a time-series prediction task:
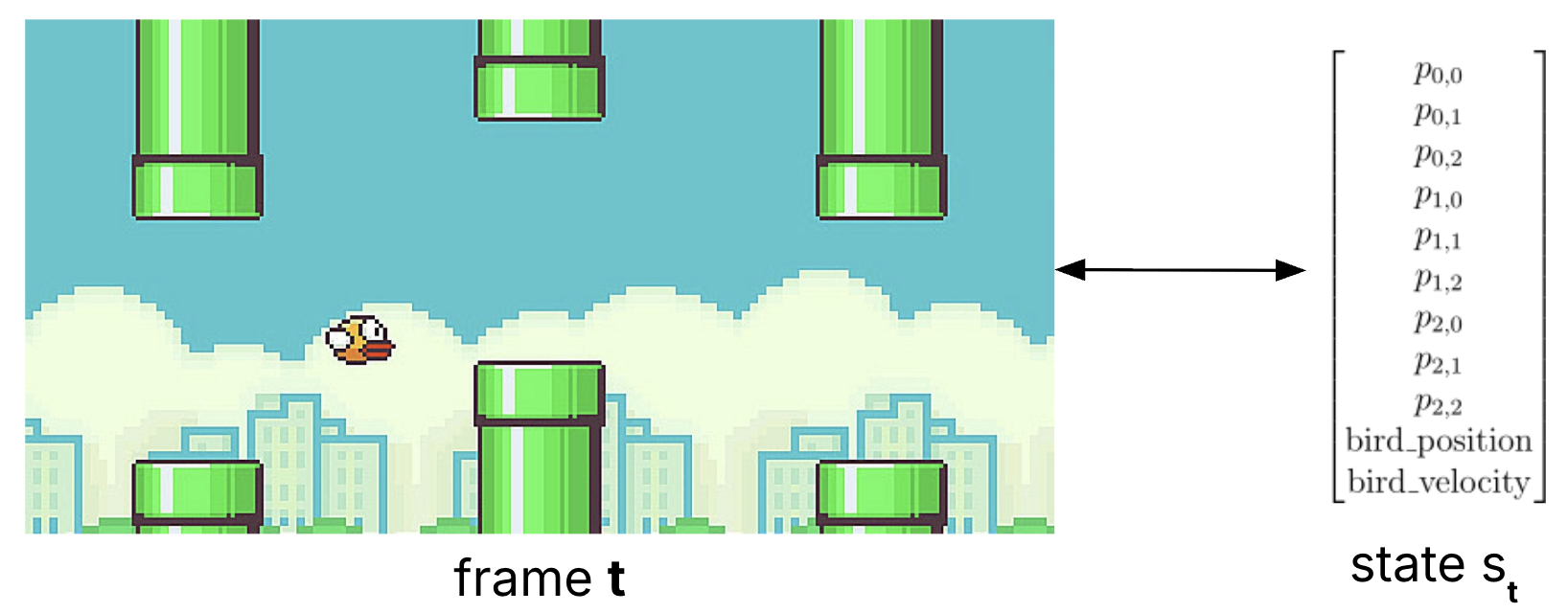
In our setup, at any given frame of flappy bird, there can be up to 3 sets of pipes, each with a top and bottom pipe. Additionally, the bird has a position and velocity for any \(t\) that can change depending on the player action. Essentially, this becomes a task of training a state-space model like MAMBA to predict the next state of the game given the current state and the player action. Reframed: \( y_t = Ch_t + Ds_t\), where \(y_t\) is the predicted state, \(h_t\) is the hidden state, and \(s_t\) is the current state. \(C\) and \(D\) are learned parameters.
Collecting Data
Prior to training the model, we needed sufficient training data. Following the format of many existing video-based diffusion models that attempt to recreate video games, we created a PPO agent to play flappy bird (eventually reaching >300 points) and collected 100 "episodes" worth of gameplay in the format of \((s_t, a_t, s_{t+1})\). We additionally collected individual (frame, action) pairs as a separate dataset for later experiments with diffusion.
Training Results
The best model we trained can be seen in action below.
During test-time, we initialize the context at ~5 frames. We attribute the wonky behavior to the complexity of our chosen representation. While the model seems to learn the configuration of the pipes correctly, it does not seem to properly track the bird's position and velocity over time (seen by the janky movement in the video). Despite this, it seems that the model is able to accurately represent the vertical positioning of the bird depending upon the position. We ran out of time before we could make improvements, but I imagine that with a more robust representation of the pipes (e.g. accounting for an off-screen/disappearing state for a pipe) and fixed dilation this approach could be extended to mimic the game more closely.
More on this coming soon...